



Magnus Linklater, founder of Bristol based SEO and content marketing agency, Bespoke Digital, discusses how to identify duplicate content issues, using tools like SiteLiner and Copyscape, and explains why it’s crucial that every web page is unique.
It amazes me that in 2017, numerous businesses still shoot themselves in the foot by duplicating content across their website. In my decade of auditing websites, this issue has never gone away, and most people seem completely oblivious to the damage done by copying blocks of text from page to page.
Ultimately, Google scans your web content to figure out which queries your website is going to be relevant for, so copying material, intentionally or not, across multiple pages causes confusion and will be penalised. The bots are looking to display only the most accurate, trustworthy information, and if they can’t differentiate between pages, they’re likely to ignore them altogether, and your rankings will stagnate as a result.
Here’s my top tips for avoiding duplicate content and staying search engine-friendly.
What effect does duplication have on SEO?
One of my clients reached out to me because their online strategy simply wasn’t working, with no idea as to why they weren’t appearing on the first page of Google.
They were a nationwide brand and much time, energy and investment had been spent creating individual sites for each city they operate in – the theory being they would dominate local search results for each region.
However, these individual sites weren’t entirely individual; they contained exactly the same material, word-for-word, apart from geographic terms and contact details. Google ultimately considers this plagiarism, because each additional site is seen to be copying whichever was first to be indexed, meaning they would be filtered out of most search results.
See what I mean by shooting yourself in the foot? I had to stress the importance of creating original, unique content across the board, and their rankings duly shot up soon after this was actioned.
While they weren’t actively trying to play the system and cheat their way to the top (they just wanted maximum gain for minimal effort), it’s easy to see why this shortcut isn’t a solid strategy for success; copying content isn’t helping the Internet at large, and Google doesn’t know whether you’ve copied yourself or a competitor, meaning it will err on the side of caution and discount your clones.
On a similar note, another client unknowingly had three identical variants of their website live and being crawled by the search bots; the development site was accessible and indexed by Google on dev.domain.co.uk, along with both the ‘www.’ and ‘non-www.’ versions of their live site. As such, only 20% of their web pages had been ranking in the SERPs, because Google was unable to accurately detect which pages to display, meaning the majority were ignored completely.
By simply ensuring that the ‘www’ version was the only indexable domain, nearly 100% of their site was cached just a few days later.
Thus, in all my years, those usually suffering duplicate content issues are wholeheartedly unaware they’re falling foul of best practice advice. Google appreciates this, which is why they simply filter your pages out rather than issuing manual penalties.
You can get away with a certain amount of duplicate content, such as legal T’s & C’s. Matt Cutts, formerly Head of Webspam at Google, explains more here:

Tackling duplicate content
Using Google Search Console, you can look into HTML Improvements – a tab that outlines issues affecting how your website is crawled, highlighting any duplicate meta descriptions or title tags, which you can then refine; duplicate content isn’t limited to the visible content of your pages, and these background elements need to be unique to give the search bots the best possible chance of differentiating between pages.
Another very common cause of duplication is where category and tag pages copy excerpts from primary blog posts, so take time to check that these are sufficiently different from each other or that the pages are set to ‘rel=noindex’.
Additionally, you can make use of the ‘site:’ search operator on Google to check whether text is appearing on more than one URL. For instance, we could copy a snippet of text from our Native Advertising vs Content Marketing article to see whether it’s accidentally indexed on different versions of the same page (‘http:’ and ‘https:’, ‘www’ and ‘non-www’, etc.:
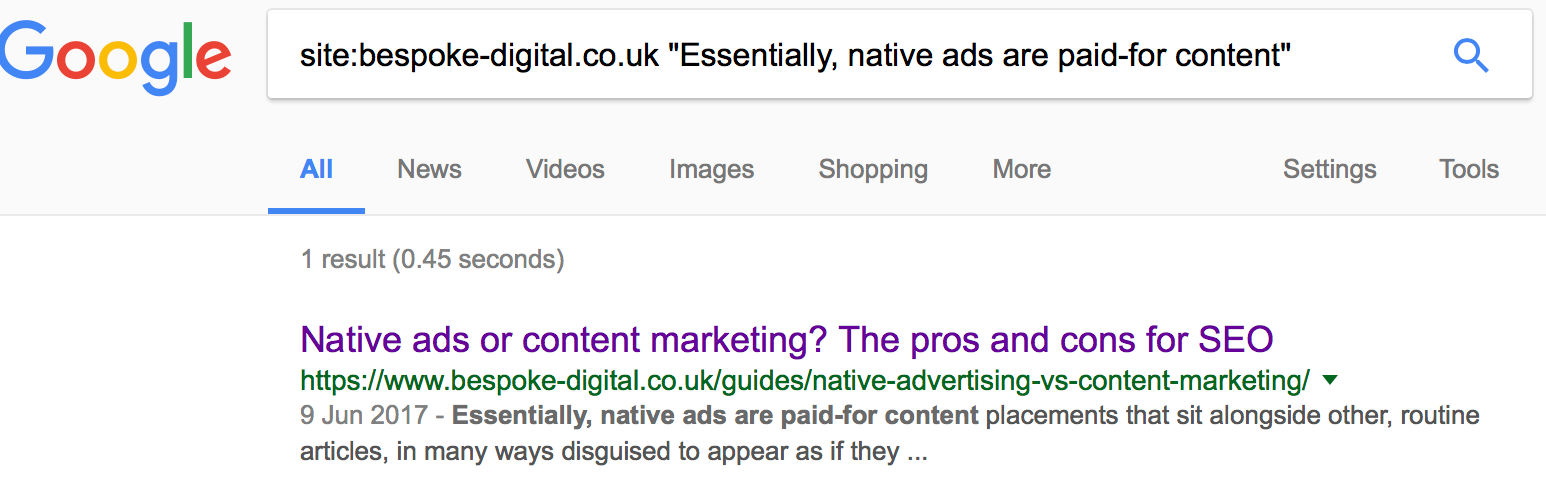

As you can see, the quoted text returns only one Google result, meaning we have no duplicate versions to upset the applecart.
If, however, you do conduct a ‘site:’ search and reveal duplication issues, you can canonicalise your pages, i.e. indicate the correct URL for Google to index. This is done via the rel=”canonical” tag, which you can read more about on Google’s guide to canonical URLs.
Additionally, it’s crucial to be strict with internal linking on your site, making sure all links point to your preferred (canonical) URL. Many businesses are now moving from ‘http:’ to the more secure ‘https:’, and if you’re in this boat you’ll have to take care to update your links, which will usually mean setting up 301 redirects, ensuring all users (people and search bots) are automatically taken to the right page.
Here’s a few other tools to help you steer clear of copied content:
- SiteLiner – perfect for carrying out quick audits, giving you a broad overview of duplicate content, as well as broken links and problems with sitemaps.
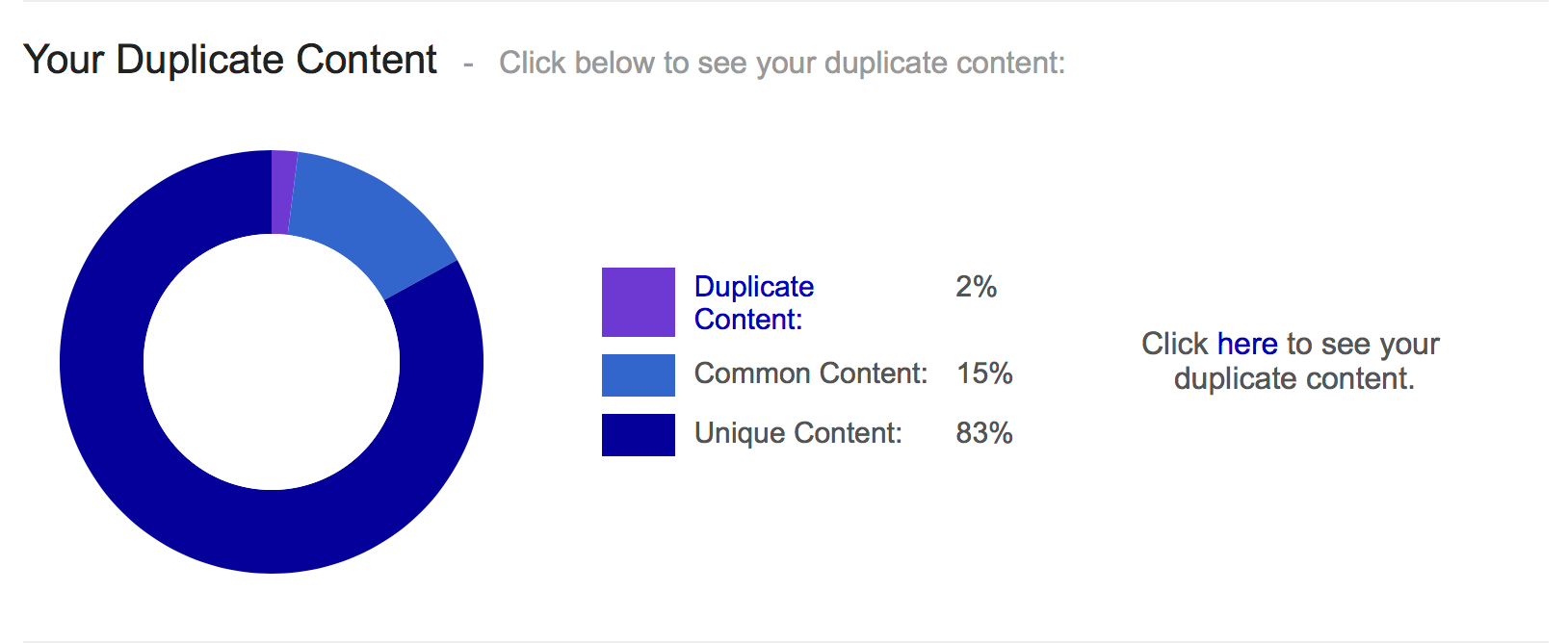

- Copyscape – The free comparison tool allows you to compare your web page by simply typing in the URLs, or copy and pasting the text, highlighting copied passages, allowing you to view them side-by-side. You can then act where necessary to re-word content to ensure it’s entirely unique.
- Grammarly – While not available on the free version, Grammarly’s premium product has a plagiarism checker, which automatically compares your content to everything else on the web, flagging up areas where you may have unknowingly (or perhaps, lazily) copied other people’s content. This saves you the embarrassment and potential legal action of infringing on another company’s copyright.
The ’near-duplicate’ content conundrum
The search engine behemoth is continually getting smarter at detecting ‘article spinning’, i.e. the act of virtually copying web content but exchanging the odd word here and there to give the appearance of uniqueness.
Fundamentally, with everything you publish online, you should make it your own and add value to the wider Internet community, not simply copy and rewording the work of others.
Quoting other people and referencing other blog posts is great, so long as you’re relatively brief and link back to the source, aiding the user experience, helping search bots understand you’re quoting rather than copying, and ultimately paying respect to the original creator.
Copying, no matter whether it’s your competitors or yourself, will leave you hamstrung and stranded in the SERPs. So don’t duplicate! Don’t duplicate! Don’t duplicate!
Magnus Linklater is the founder of Bristol based SEO and content marketing agency, Bespoke Digital.